
Mūsdienās jēdzienu „mākslīgais intelekts” (MI) ierasti lieto gan dažādu nozaru terminoloģijā, gan plašsaziņas līdzekļos un sadzīvē, tomēr vienotas definīcijas tam nav un izpratne par to mēdz būt visai atšķirīga. Publicistikā ar MI nereti apzīmē datorprogrammas, kas patlaban vēl ir tīra zinātniskā fantastika, proti, tādas skaitļošanas sistēmas, kam piemīt pašapzināšanās spēja. Zinātniskās pētniecības jomā MI vairāk saistās ar mākslīgajiem neironu tīkliem, kas šobrīd jau veic ļoti komplicētus uzdevumus – objektu atpazīšanu, tulkošanu no dažādām valodām, transportlīdzekļu autonomu vadīšanu, interaktīvu sarunāšanos (virtuālais asistents jeb čatbots) u. tml.
Pašreizējo mākslīgā intelekta „revolūciju” sekmē ne tik daudz mūsdienu fundamentālās zinātnes atklājumi, cik radusies iespēja efektīvi izmantot senākas zinātniskās idejas, piemēram, Beijesa statistiku (18. gadsimts) vai formālos neironus (1943), kombinācijā ar vienu no mašīnmācīšanās apakšnozarēm – dziļo mašīnmācīšanos (deep learning).
Vēsturiski mākslīgā intelekta attīstībā ir bijuši divi strauja uzplaukuma periodi: vispirms pagājušā gadsimta piecdesmitajos un sešdesmitajos gados un vēlāk astoņdesmitajos gados. Tagadējais izrāviens mākslīgā intelekta pētniecībā aizsākās 21. gadsimta otrajā desmitgadē, pateicoties dziļās mašīnmācīšanās algoritmiem apvienojumā ar pieeju apjomīgam datu kopumam un augstas veiktspējas skaitļošanai, ko pārsvarā nodrošina grafisko procesoru (graphics processing unit – GPU) sniegums.
Īlons Masks un Bills Geitss ir prognozējuši, ka mākslīgais intelekts pārspēs cilvēka smadzeņu spējas jau tuvāko gadu laikā. Patiesi, šķiet, nekas nespēs apturēt mākslīgā intelekta uzvaras gājienu, jo skaitļošanas resursu un pieejamo datu apjoms pieaug eksponenciāli. Tomēr šajās prognozēs nav ņemts vērā fakts, ka pašreizējie uz dziļo mašīnmācīšanos balstītie mākslīgā intelekta modeļi izmaksā ārkārtīgi dārgi un turklāt paredz milzīgus ieguldījumus ne tikai dolāros un centos, bet arī patērējamās enerģijas ziņā. Šodienas mākslīgais intelekts nav maģija. Tā ir augsta līmeņa matemātika, kas var palīdzēt mašīnām izpildīt precīzi definētus intelektuālus uzdevumus, pārspējot cilvēka veikumu.
Īsumā aplūkosim šībrīža dziļās mašīnmācīšanās modeļu darbību. To operācijas nav tik gudras kā tās, ko veic cilvēka smadzenes, jo informāciju tie neapgūst strukturētā veidā, bet liek lietā „brutāla spēka” (brute force) statistiskās metodes. Piemēram, ja vēlaties apmācīt dziļās mašīnmācīšanās modeli vizuāli identificēt noteikta veida objektu, tad parādiet tam daudzus tūkstošus attēlu, kuros šo objektu marķējuši cilvēki. Atšķirībā no cilvēka dziļās mašīnmācīšanās modelis pēc apmācības vienalga nespēs saprast cēloņsakarības, kontekstu vai analoģijas, ko raisa attēls, ja vien tas nebūs īpaši apmācīts konkrētā uzdevuma veikšanai.
Skaitļošanas jauda, kas izlietota mākslīgā intelekta sistēmu apmācībai, ir strauji eksponenciāli pieaugusi tieši dziļās mašīnmācīšanās laikmetā (1. att.). Viegli saprast, ka katra skaitļošanas darbība patērē noteiktu daudzumu enerģijas. Piemēram, populārajam modelim GPT-3 ir 175 miljardi mašīnmācīšanās parametru un aprēķināts, ka energopatēriņš šā modeļa apmācībai tipiskā datu centrā ir 1404 MWh [1]. Šajā gadījumā ir analizēta tikai viena apmācības sesija modelim, kas veic dažādus uzdevumus dabiskās valodas jomā. Ja turpretī mākslīgais intelekts censtos tuvoties cilvēka saprāta līmenim, tad enerģijas patēriņš būtu neskaitāmas reizes lielāks.
Lai samazinātu MI enerģijas patēriņu, jāstrādā gan pie dziļās mašīnmācīšanās modeļu uzlabošanas, gan pie energoefektīvāku grafisko procesoru izveides. Salīdzinot cilvēka smadzeņu enerģijas patēriņu (daži desmiti vatu visas domāšanas spējas nodrošinājumam) ar to, kāds nepieciešams uz dziļo mašīnmācīšanos balstītam mākslīgajam intelektam, iezīmējas milzīga atšķirība (piemēram, lai iemācītos vairāku miljonu attēlu kopā atpazīt pingvīnu, MI energopatēriņš būs vairāki kilovati).
Ceļš uz mākslīgo intelektu, kas darbojas līdzīgi kā smadzenes
Ja mums izdotos mākslīgā intelekta datorprogrammās pielietot tehnikas, kas nosaka cilvēka prāta darbību, tad pavērtos plašas iespējas būtiski samazināt skaitļošanā izlietotās enerģijas apjomu. Brutāla spēka statistiskais modelis patērē ļoti daudz enerģijas, jo tā darbība būtiski atšķiras no cilvēka smadzeņu darbības. Mākslīgajam intelektam, atšķirībā no cilvēka smadzenēm, patlaban ir vajadzīgi šādi parametri:
- miljoni vai miljardi apmācības paraugu;
- daudzi apmācības cikli;
- pārapmācība, tiklīdz parādās jauna informācija;
- daudz reizināšanu operāciju ar svaru koeficientiem.
Lai kāpinātu mākslīgā intelekta darbības efektivitāti, datorzinātņu un neirozinātņu pētniecībā jāpievērš uzmanība vairākiem svarīgiem aspektiem.
Notikumvirzīta aktivitāte un skrajums (sparsity)
Smadzenēs nervu sistēmas darbība ir notikumvirzīta un skraja, jo atbildes reakcijā uz sensorisku kairinājumu (lai kas to izraisītu – saruna, abstrakta doma, iecere u. c.) aktivizējas tikai ļoti neliela daļa neironu (vidēji mazāk nekā 2%). Tas pats sakāms par nervu sistēmas savienotību, jo nervu šūna (neirons) no teju visiem apkārtējiem neironiem saņem relatīvi maz impulsu (bieži mazāk nekā 5%). Pateicoties notikumvirzītajai aktivitātei, smadzeņu darbība ir ārkārtīgi energoefektīva. Mākslīgajā neironu tīklā šis aspekts būtu „pārtulkojams” šādi: neironu aktivitātē kā aktivizācijas skrajums un neironu savienotībā kā svara koeficientu skrajums [2]. Tā kā skrajās struktūrās ir daudz nulles elementu, proti, mākslīgajā neironu tīklā skrajums paradās gan svaru koeficientos, gan aktivizācijas funkcijās, tad reizinājumu nepieciešams izskaitļot vienīgi tad, ja tas satur nenulles elementu, jo lielu daļu reizinājumu (ideālas smadzeņu darbības imitācijas gadījumā ~98%) var izslēgt.
Strukturēti dati
Ārpasaules modelim mūsu smadzenēs ir trīsdimensionāla uzbūve, kas iemantota sensoriskās informācijas plūsmas un pārvades ceļā. Šāds trīsdimensionāls modelis reprezentē cilvēka ķermeņa novietojumu pret vidi un citiem objektiem un dod iespēju veidot savstarpējas attiecības. Piemēram, tas mums ļauj domās pārvietot lietas, mainīt to stāvokli un izskatu. Mēs spējam konceptuāli aptvert, ka vienam objektam var būt saikne ar citu objektu, un tāpēc mums nevajag aplūkot miljoniem paraugu, kas demonstrētu šo objektu dažādās attieksmes. Mēs varam iztēloties lietas arīdzan atšķirīgās krāsās, lai gan reālajā dzīvē tādas neesam redzējuši. Ja MI strādātu ar strukturētiem datiem, nevis ar pikseļiem vai to grupām, tad, lai tas spētu atpazīt objektu dažādās ainās (tajā skaitā tādās, kurām nebūtu īpaši apmācīts). apmācība būtu nepieciešama ievērojami mazākām datu kopām. Tas dotu iespēju būtiski samazināt gan apmācāmās datu kopas izmēru, gan apmācības procesa jaudu, nezaudējot kvalitāti.
Inkrementāla un vairākuzdevumu apmācība
Kad mūsu smadzenesuztver jaunu informāciju, piemēram, ierauga jaunu objektu, mēs cenšamies to salīdzināt ar jau pazīstamiem objektiem ar tiem raksturīgām īpašībām, lai rastu kopīgo un arī atšķirīgo. Tādējādi mēs gūstam informāciju par jauno objektu, lietderīgi izmantojot iepriekš zināmo. Līdz šim nav skaidrs precīzs mehānisms, kā bioloģiskais neirons konvertē ienākošos signālus darbības potenciālos (proti, spriegumos). Tomēr ir skaidrs, ka matemātiskais punkveida neironu modelis, kas sastāv no lineāras svērtas ieejas vērtību summas ar sekojošu nelinearitāti (1907. gadā ierosināja L. Lapiks) un kas joprojām kalpo kā dziļās mašīnmācīšanās sistēmu pamats, ir vienkāršots un nefunkcionē atbilstoši cilvēka smadzeņu pieejai. Bioloģiskie piramidālie neironi ir būtiski sarežģītāki un demonstrē dažnedažādas kompleksas nelineāras, dendrītiem specifiskas integratīvas īpašības [3]. Līdz ar to MI piemīt vairākas nepilnības. Piemēram, MI katrā apmācības iterācijā daudzus savus savienojumus pārraksta un tāpēc strauji zaudē iepriekš gūtās zināšanas. Cita nepilnība saistās ar nespēju strādāt vairākuzdevumu režīmā, proti, ierobežotām iespējām mācīties risināt daudzus uzdevumus vienlaicīgi. Tā kā MI nespēj izmantot priekšrocības, ko paver inkrementālā un vairākuzdevumu mācīšanās, tad salīdzinājumā ar cilvēka smadzenēm tā apmācības process ir ilgāks un tam vajag daudz vairāk iterāciju, līdz ar to krietni lielāks ir arī enerģijas patēriņš.
Pielāgota skaitļošanas aparatūra
Patlaban pieejamās pusvadītāju iekārtas (piemēram, grafiskie procesori) ir orientētas uz ļoti apjomīgu dziļās mašīnmācīšanās skaitļošanu, kurā apmācība norisinās nestrukturēti un informācija tiek traktēta kā vienmēr un visur esoša. Taču, ja gribam attīstīt MI, kas tiecas strādāt pēc smadzeņu darbības principiem, mums vajadzīga tam atbilstoša skaitļošanas aparatūra, kas operē ar strukturētiem datiem un veic pastāvīgu mācīšanos saskaņā ar notikumvirzības un skrajuma specifiku. Turklāt tai jābūt iekļautai energoefektīvā pusvadītāju platformā. Patlaban jau ir zināmas tehnoloģijas, kas energoefektivitātē pārspēj tradicionālos risinājumus (piemēram, notikumvirzīta signālu apstrāde, saspiedošā iztvere, dziļā un vairākuzdevumu nostiprinošā apmācība, pulsējošie neironu tīkli (Spiking Neural Networks – SSN), kā arī heterogēnas iegultās (System-on-Chip) skaitļošanas platformas, un tās varētu tikt izmantotas kā piemērs jaunas, smadzeņu darbību imitējošas MI funkcionalitātes attīstībā. Domājot par tālāku nākotni, mēs varam iztēloties arhitektūru, kas būtu optimāli pielāgota cilvēka prāta snieguma atdarināšanai un arī enerģijas patēriņa ziņā darbotos tikpat efektīvi kā smadzenes.
Secinājumi
Lai nākotnē mākslīgā intelekta iespējas pietuvotos cilvēka smadzeņu funkcionalitātei un šis mērķis tiktu sasniegts ar racionāli samērīgu enerģijas patēriņu, nepieciešams attīstīt MI, kas strādā gudrāk, nevis smagāk. Ievērojamus uzlabojumus energopatēriņa jomā var panākt tikai tad, ja kompleksi samazina skaitļošanas operāciju, apmācības paraugu un sesiju skaitu, vienlaikus attīstot aparatūras tehnoloģijas, kas pielāgotas šo uzdevumu īstenošanai. Ja mums būs jāveic desmitreiz mazāk aprēķinu, jāizlieto desmitreiz mazāk apmācības paraugu, jārealizē desmitreiz mazāk apmācības sesiju un visas šīs darbības veiks desmitreiz efektīvāks dators, tad vispārējā sistēma pietuvosies cilvēka smadzeņu spējām un arī būs desmittūkstoš reižu efektīvāka no enerģijas patēriņa skatpunkta!
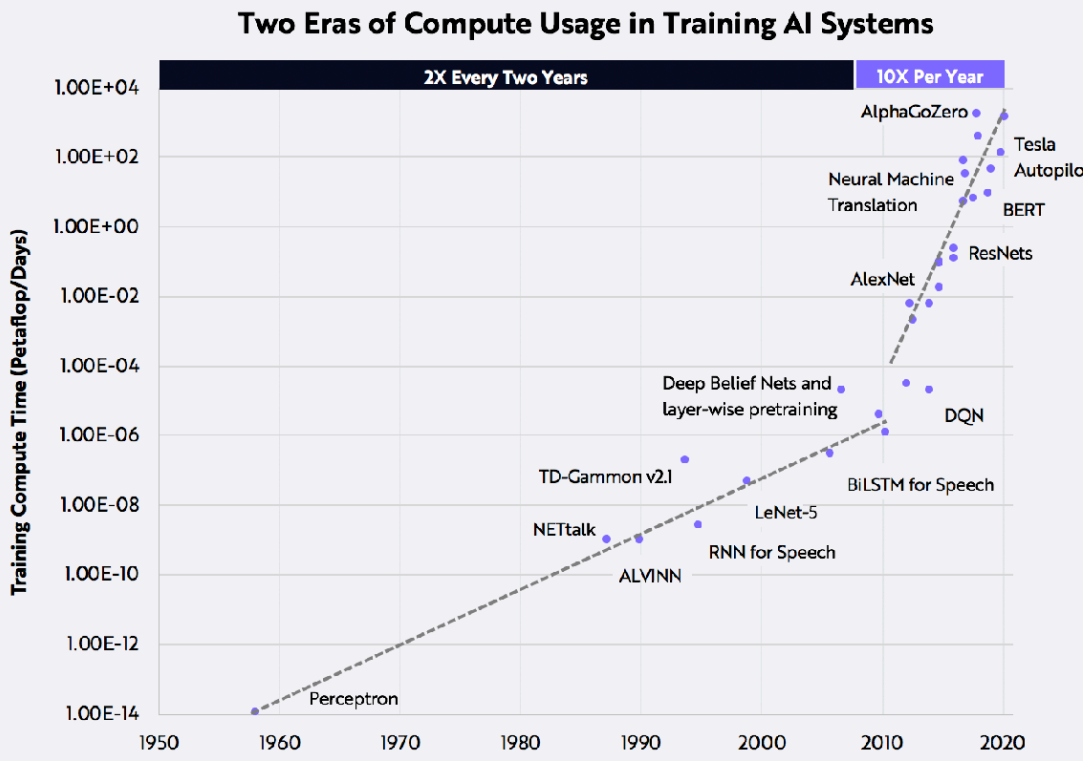
1. attēls. Skaitļošanas jaudas izlietojums MI sistēmu apmācībai
Avots:
Atsauces
Doing AI without breaking the bank: yours, or the planet’s. https://blog.scaleway.com/doing-ai-without-breaking-the-bank-yours-or-the-planets/
Hunter K., Spracklen L., Ahmad S. Two sparsities are better than one: unlocking the performance benefits of sparse – sparse networks. Neuromorph. Comput. Eng., 2022. Vol. 2, No. 3. 034004. DOI: 10.1088/2634-4386/ac7c8a
Iyer A., Grewal K., Velu A., Souza L. O., Forest J., Ahmad S. Avoiding catastrophe: Active dendrites enable multi-task learning in dynamic environments. Front. Neurorobot., 2022, Vol. 16, 846219.
Raksts sākotnēji publicēts angļu valodā LZA izdevumā Latvian Academy of Sciences Yearbook 2023 ar nosaukumu Energy Efficiency: Artificial vs Human Intelligence.